Using Orca Locally
Orca can also be run independently of the Synapse Studio. The following steps detail how to use Orca in a local environment.
Prerequisites
Hardware
The Orca container automatically detects and optimizes for the available number of vCPU cores and RAM. To run efficiently, the following configuration is recommended:
- 4 vCPU cores and 16 GB of RAM
If more vCPU cores and memory are available, they can be added in a ratio of 3-4 GB RAM per core. While possible to run the container with fewer vCPU cores and less memory, performance would degrade significantly, especially with image data depicting areas with a high density of target features.
Nvidia GPU with a high FP16 (half-precision) performance, e.g.
- Tesla T4 (recommended)
Software
Steps
-
Create a new directory for Orca's
submissionandresultsfolders.mkdir -p <directory_name>/{submission,results} -
Log in
Then enter the password.docker login orcacr.azurecr.io -u <username>The
<username>and password can be found in the Orca web app.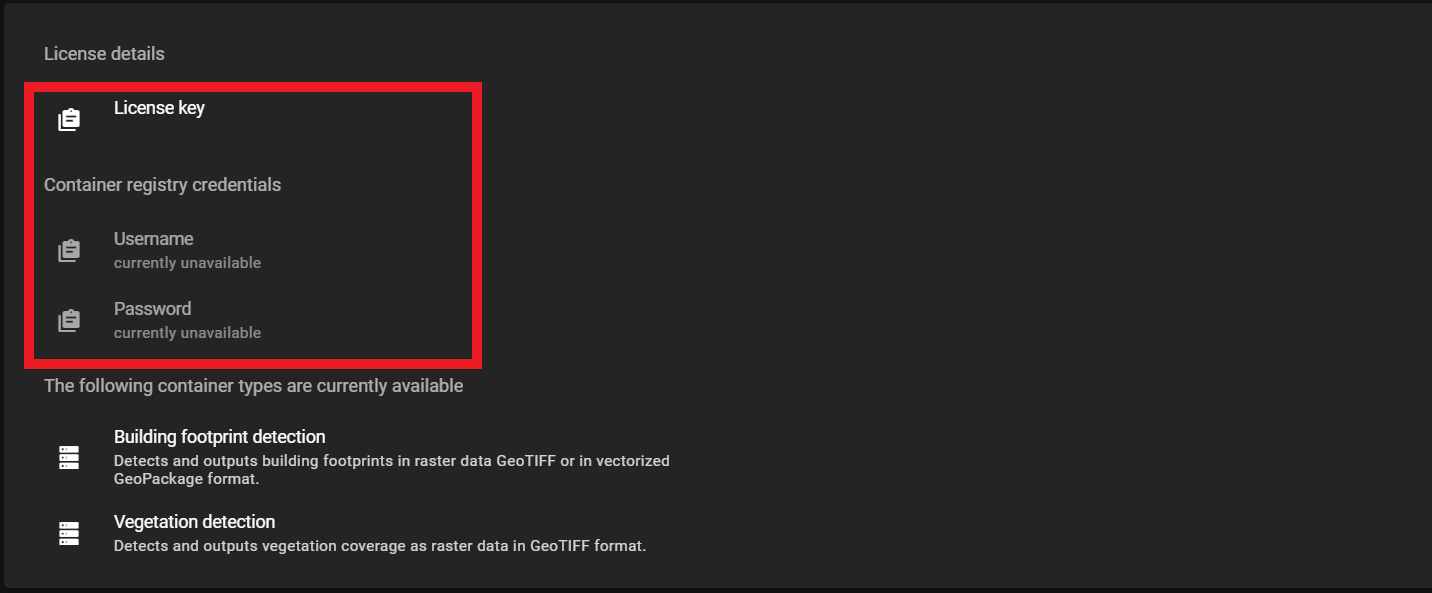
The user name and password can be found in the web app -
Run Orca
The following command can be used to run the Orca container. Run this command in the parent directory containing
<directory_name>created in step 1.Note
The default runtime needs to be set to the Nvidia Container Runtime. In the command below, the flag
--gpus all \should solve this issue. For more information see: Nvidia Container Runtimedocker run -it \ --gpus all \ -v $(pwd)/<directory_name>:/data \ -e LOGGING_RENDERER=CONSOLE \ -e BSHRK_RUN_VECTORIZATION=true \ -e BSHRK_LICENSE_ID=<license_key> \ orcacr.azurecr.io/orca/<container_image>-
Make sure that
<directory_name>in the command above is the same as created in step 1. -
To turn vectorization off, change the value of
BSHRK_RUN_VECTORIZATION=tofalse. Change the value back totrueto turn vectorization back on.Currently, the vectorization option is only available for Orca's building footprint detection.
runVectorization Error
When the vectorization process is run with a detection class container that does not support the process (currently BSHRK-W-VGD-21), it will result in the following error message:
Traceback (most recent call last): File "/srv/scripts/all_in_one_pipeline.py", line 160, in <module> main() File "/srv/scripts/all_in_one_pipeline.py", line 146, in main raise ValueError(f"Vectorization is not supported for inference type {inference_type}. " ValueError: Vectorization is not supported for inference type InferenceType.VEGETATION_DETECTION -
The
<license_key>can also be found in Orca web app as shown above. -
The
<container_image>can be copied from the web app. Instead of a version number as shown in in the web app:latestmay be used to pull the latest image.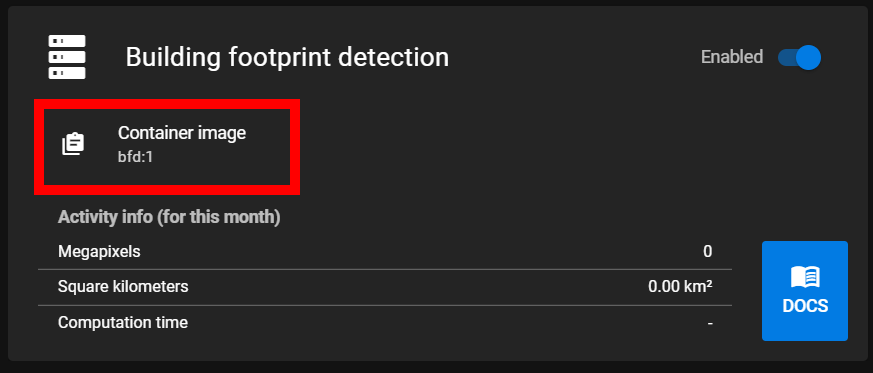
Copy container image
-
Input and Output Files
Input files need to be in GeoTIFF format and meet the specified data requirements. When the container is run, it will run the detection processes on every file in the submission folder created in step 1 above. Resulting files are written to the results folder.
The filename of the input file is retained. Output files from inference will have an _inference postfix. results from the vectorization step are in GeoPackage format and will have a _vectorization postfix. The postfix will also indicate the detection class run showing either _bfd or _vgd for building footprint detection and vegetation detection respectively.
Example
big-city.tif
big-city_inference_bfd.tif (Building footprint detection)
big-city_inference_vgd.tif (Vegetation Detection)
big-city_vectorization_bfd.gpkg