Using Orca on Synapse
This guide describes how to operate the Orca container pipeline after initial Orca setup.
Settings
Before running the pipeline, be sure to enter a value in each field in the Orca settings menu.
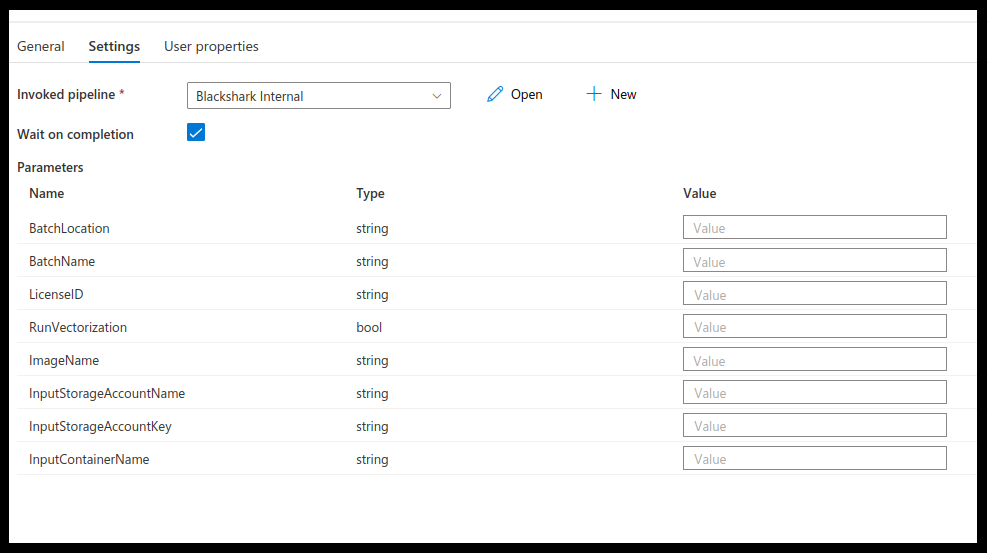
After entering all Orca settings, click publish all at the top of the Synapse studio. Below is a more in depth look at each setting.
Batch Location and Name
Enter batch location and name. The location should be the same as that in step 1 of Subscription and Web App in the initial Orca setup.
License ID
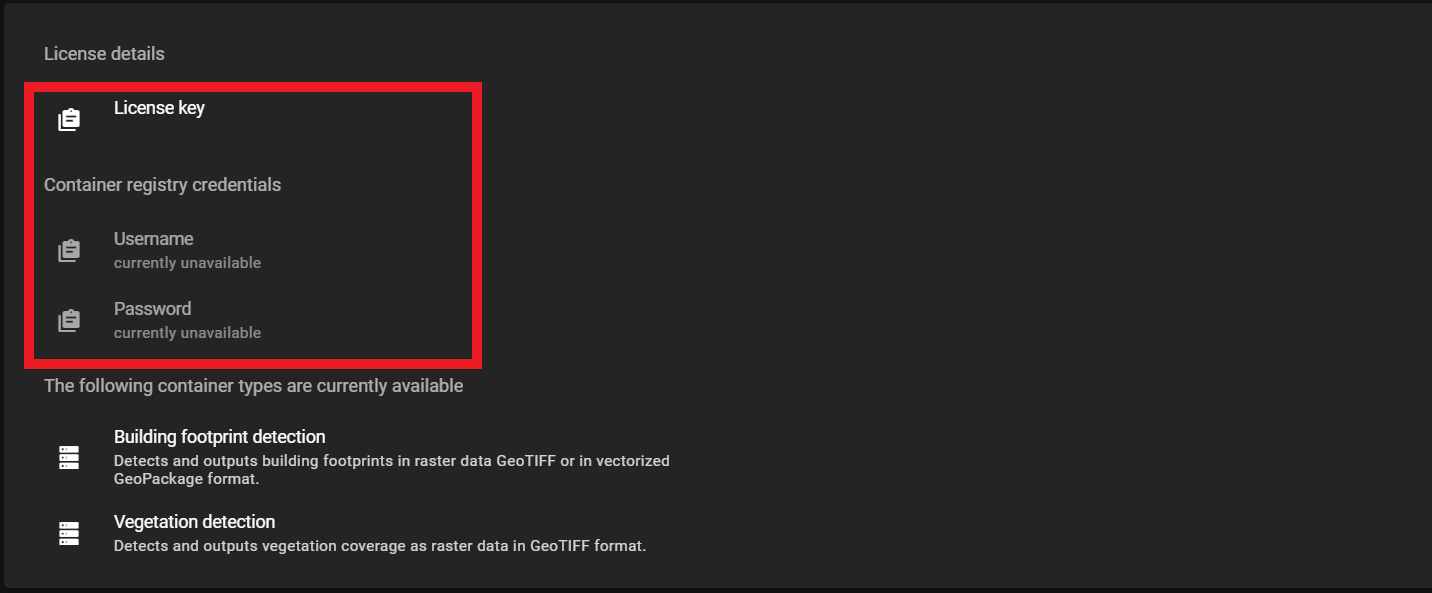
In order to run Orca, it is necessary to verify the subscription through Azure Analytics. Copy the license key provided on the Orca web app and paste it into the field provided under the pipeline parameters in the Synapse dashboard interface.
Run Vectorization
Target feature class detection provided by Orca is delivered as a heatmap generated following the inference process in GeoTIFF format. The inference process will result in raster data displayed as pixelated images. The output of the inference process can be vectorized resulting in a GeoPackage file containing polygons.
graph LR
A[Input Imagery<br>Aerial or satellite imagery<br>Geotiff/Cog] --> B[[Inference<br>process]];
B --> C[Inference Results<br>Geotiff file];
C --> D{runVectorization};
D -->|true| E[[Vectorization<br>process]];
E --> F[Vectorized Results<br>GeoPackage file]
To turn vectorization on enter true in the field provided under pipeline parameters for runVectorization.
To turn vectorization off enter false in this field.
Currently, the vectorization option is only available for Orca's building footprint detection.
runVectorization Error
When the vectorization process is run with a detection class container that does not support the process( currently BSHRK-W-VGD-21), it will result in the following error message:
Traceback (most recent call last):
File "/srv/scripts/all_in_one_pipeline.py", line 160, in <module>
main()
File "/srv/scripts/all_in_one_pipeline.py", line 146, in main
raise ValueError(f"Vectorization is not supported for inference type {inference_type}. "
ValueError: Vectorization is not supported for inference type InferenceType.VEGETATION_DETECTION
Image Name
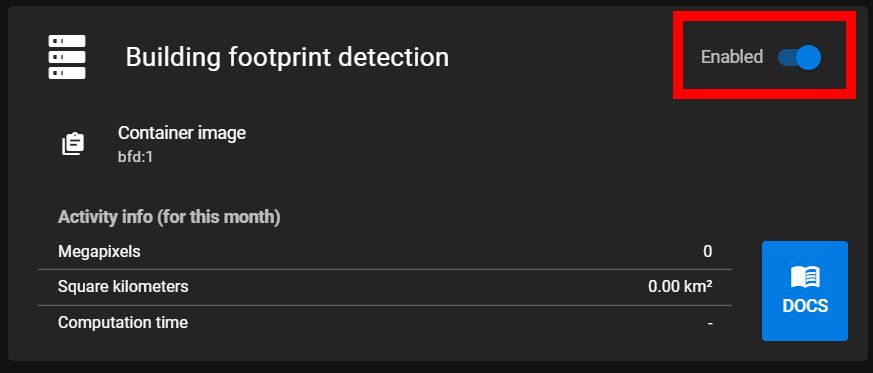
First, enable desired detection classes by toggling the container to "enabled" as shown in the image below.
Then, copy the container image from the web app.
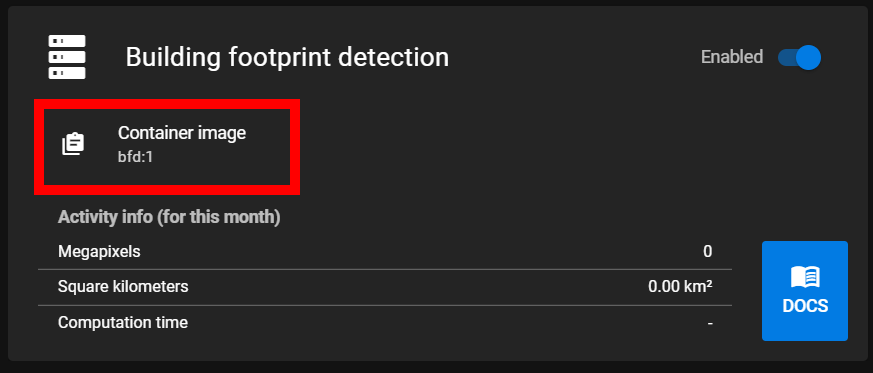
Paste this image into the pipeline parameters in the field provided for container image.
Input Storage Account Name and Key
The storage account name should be the folder named rawdata<random> as described in step 4 of Pipeline Setup of the Orca initial setup.
After navigating to the storage account folder click access keys from the menu on the left. Next click show keys at the top of the access keys page. Then copy the first key named 'key' and paste it into the storage account key field in the Orca settings.
Input Container Name
Enter the name of the container created in Step 4 of Pipeline Setup. This is the container where the input file is located.
Input and Output Files
Input files need to be in GeoTIFF format and meet the specified data requirements. When the container is run, it will run the detection processes on every file in the input folder created as part of initial setup. Resulting files are written to the results folder.
The resultsfolder is created after running the Orca pipeline for the first time.
The filename of the input file is retained. Output files from inference will have an _inference postfix. results from the vectorization step are in GeoPackage format and will have a _vectorization postfix. The postfix will also indicate the detection class run showing either _bfd or _vgd for building footprint detection and vegetation detection respectively.
Example
big-city.tif
big-city_inference_bfd.tif (Building footprint detection)
big-city_inference_vgd.tif (Vegetation Detection)
big-city_vectorization_bfd.gpkg